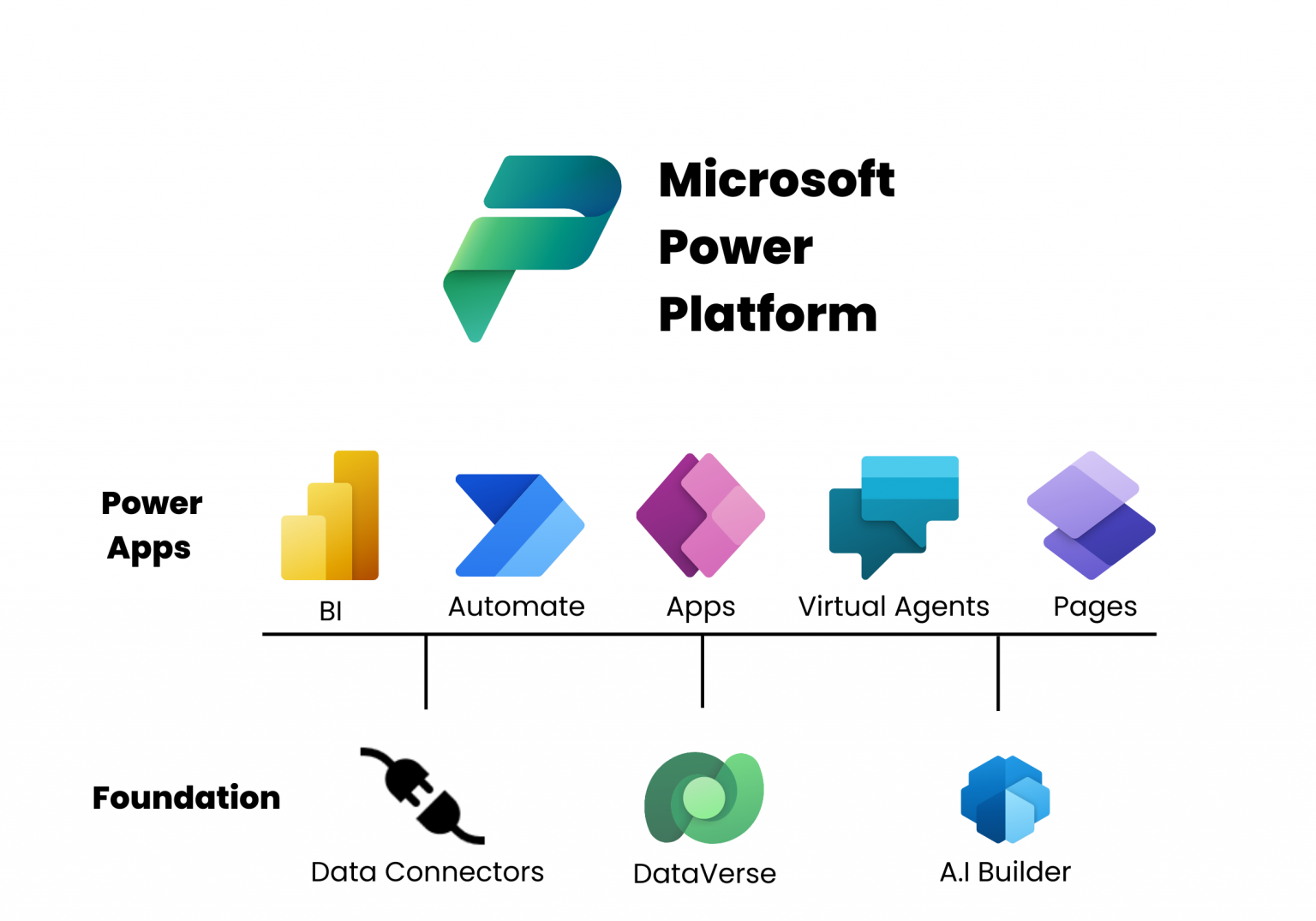
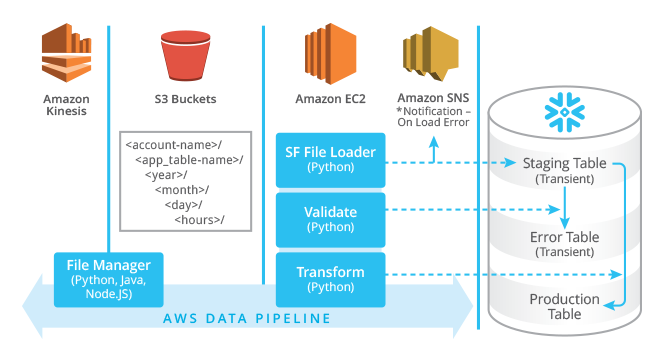
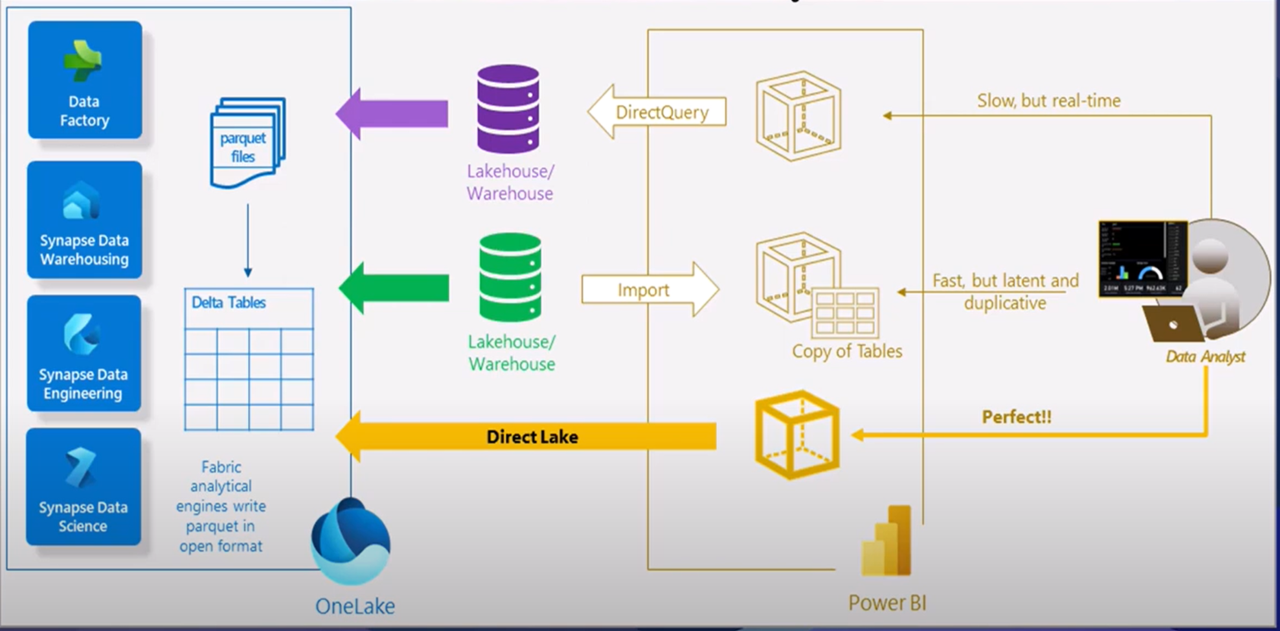
Large Language Models (LLMs) have functioned as a revolutionary force in the interaction between humans and machines, as well as the means of information processing. Such models powered by complex algorithms and big data are revolutionizing the abilities of AI in the different fields. It is getting a lot of attention, though they took several years in the making. Huge organizations like IBM have exhausted themselves to fund Natural Language Understanding (NLU) and Natural Language Processing (NLP) technologies, making these great models possible. They are a perfect example of what is known as foundation models – trained on large data and capable of addressing numerous tasks and applications. This is a major shift when compared to the traditional way of creating individual models for a given specific application, which results in a more efficient performance, and definitely a more effective use of resources.
Large Language Models (LLMs) have functioned as a revolutionary force in the interaction between humans and machines, as well as the means of information processing. Such models powered by complex algorithms and big data are revolutionizing the abilities of AI in the different fields. It is getting a lot of attention, though they took several years in the making. Huge organizations like IBM have exhausted themselves to fund Natural Language Understanding (NLU) and Natural Language Processing (NLP) technologies, making these great models possible. They are a perfect example of what is known as foundation models – trained on large data and capable of addressing numerous tasks and applications. This is a major shift when compared to the traditional way of creating individual models for a given specific application, which results in a more efficient performance, and definitely a more effective use of resources.
Understanding Large Language Models
The Large Language Models (LLM) are among the subsets of the developed foundation models which are trained on large amounts of textual data to be able to understand natural language and produce content of different forms to perform several purposes. They represent a substantial advancement in NLP and artificial intelligence, and they are widely available to the general public via interfaces such as Open AI's Chat GPT-3 and GPT-4, which have received Microsoft approval.
 The operation of LLMs relies on the application of deep learning algorithms and massive quantities of textual material. These models are normally developed using the transformer architecture, which has shown great competency in dealing with sequential data such as text inputs. The main constituents of LLMs are layers of neural networks comprising parameters that can be adjusted during the training process (Fine-tuning) in addition, the given technique is complemented with an attention mechanism directing to specific fragments of datasets.
The operation of LLMs relies on the application of deep learning algorithms and massive quantities of textual material. These models are normally developed using the transformer architecture, which has shown great competency in dealing with sequential data such as text inputs. The main constituents of LLMs are layers of neural networks comprising parameters that can be adjusted during the training process (Fine-tuning) in addition, the given technique is complemented with an attention mechanism directing to specific fragments of datasets.
Training these Models, learn to predict the next word of a sentence given some context from the previous words in the sentence. They assign a probability score with the word sequence, which has been tokenized further and divided into small sequences of characters. These tokens are then converted to embeddings or, in other words, the numeric representation of this context.
After being trained, these models exert their creativity by predetermining the next word given an input and the patterns and knowledge that the model has under its belt. The end product is language generation that is semantically sound and relevant in its context across various applications.
It is crucial to ensure that enterprise-grade LLMs are ready for use without posing liability or reputational risks to organizations to enhance the model’s performance by prompt engineering, prompt tuning, fine-tuning, or reinforcement learning with human feedback; otherwise, it may contain biases, hate speech, or “hallucinations, ” such as wrong answers that are factually incorrect.
Generative AI: refers to algorithms that create new content (text, photos, music, or other data) from scratch. It leverages LLMs to produce human-like text that is indistinguishable from human-created content. This capability profoundly impacts creative industries, customer service, and content creation.
Retrieval-Augmented Generation (RAG) combines LLMs' strengths with external knowledge bases, allowing the model to retrieve relevant information from large datasets and integrate it into generated content. This approach enhances accuracy, relevance, and factual correctness.
Prompt Flow: Prompt flow involves designing and structuring prompts to guide LLM output effectively. Carefully crafting input prompts influences model responses to align with specific goals, tone, or style, crucial in applications requiring precise and contextually appropriate responses, such as customer support or educational tools.
Types of Large Language Models
- Autoregressive Models: Generate text by predicting the next word in a sequence based on preceding words, excelling at coherent and contextually relevant text generation. E.g. GPT-3, GPT-4
- Autoencoding Models: Designed for understanding and interpreting text, effective for tasks like text classification, sentiment analysis, and question answering. E.g. BERT, RoBERTa
- Seq2Seq Models: Tailored for tasks where input and output are sequences, such as translation and summarization, converting one sequence into another while preserving meaning. e.g. T5, BART
- Multimodal Models: Handle multiple types of data, such as text and images, integrating various forms of data for comprehensive AI capabilities. E.g. DALL·E, Gemini
What model to use?
When deciding which LLM to use, various variables should be considered, including cost, availability, performance, and capability:
- Gpt-35-turbo: This model is affordable, works well, and, despite its ChatGPT name, may be used for a variety of purposes other than chat and communication.
- gpt-35-turbo-16k, gpt-4, or gpt-4-32k: These versions are suitable if you want more than 4,096 tokens or support greater prompts. However, these models are more expensive, may be slower, and have limited availability.
- Embedding models are appropriate for applications such as search, grouping, recommendations, and anomaly detection. Computers can readily use a vector of numbers to construct the embedding. An embedding is a dense representation of a text's semantic meaning. The distance between two embeddings in the vector space correlates with semantic similarity.
- DALL-E: This model creates pictures using text cues. DALL-E varies from previous language models in that it produces an image rather than text.
- Whisper: This model was trained using a huge dataset of English audio and text. Whisper is designed for speech-to-text applications such as audio transcription. It can be used to transcribe audio files that contain speech in languages other than English, yet the model produces English text. Use Whisper to quickly transcribe audio files one at a time, translate audio from foreign languages into English, or give the model a hint to guide the output.

Leveraging LLMs in Azure Machine Learning Studio
Azure Machine Learning Studio provides a robust platform for developing, deploying, and managing machine learning models, including LLMs. Here's a step-by-step guide:
- Setup Azure Machine Learning Workspace: Create a workspace and configure compute resources.
- Data Preparation: Collect and preprocess data using Azure Data Factory or Azure Synapse Analytics.
- Model Selection and Training: Choose or import a pre-trained LLM, then fine-tune it using your dataset.
- Model Deployment: Deploy the model as a web service, configure endpoints, and integrate with applications via REST APIs.
- Utilize Retrieval-Augmented Generation: Connect the model to Azure Cognitive Search or other knowledge bases to enhance capabilities.
- Optimize with Prompt Flow: Design and test prompts for desired model behavior, using Azure's experimentation tools to refine them.
- Monitoring and Maintenance: Continuously monitor performance and update/retrain the model as needed.
Harnessing the Potential of LLMs
LLMs revolutionize business processes and drive innovation across industries. Key use cases include:
- Text Generation: Automate content creation and enhance quality with retrieval-augmented generation (RAG).
- Content Summarization: Summarize lengthy documents, articles, and reports.
- AI Assistants: Develop chatbots for customer queries, backend tasks, and information provision.
- Code Generation: Assist developers in writing, debugging, and securing code across multiple languages.
- Sentiment Analysis: Analyze customer feedback to improve brand reputation management.
- Language Translation: Provide accurate, contextually relevant translations for global reach.
- Accessibility: Assist individuals with disabilities through text-to-speech applications and accessible content generation.